前言
计算机网络:是一个将分散的、具有独立功能的计算机系统,通过通信设备与线路连接起来,由功能完善的软件实现资源共享和信息传递的系统。
计网的东西很多,但具体底层的东西,现在还没必要去深究,前端中的网络知识更多是关注偏上层的内容,如TCP、HTTP等,以及相关的技术和工具。
分层体系结构
计算机网络是个复杂的系统,分层可将复杂的问题转为若干较小的局部问题,易于研究与处理。
常见的分层体系结构:
- OSI七层模型 OSI(Open System Interconnect)开放式系统互联。是ISO(国际标准化组织)组织在1985年研究的网络互连模型。
- TCP/IP四层模型 OSI是一种理论下的模型,而TCP/IP已被广泛使用,成为网络互联事实上的标准。
- 五层原理模型 便于对计算机网络进行理解和学习的教学模型。
OSI七层模型:
- 物理层 传输数据的物理媒介,如电缆、光纤、无线电波等。
- 数据链路层 传输数据的链路,如以太网、无线局域网等。
- 网络层 IP寻址和路由选择。
- 传输层 建立进程间的端到端连接,如TCP、UDP。
- 会话层 建立会话连接。
- 表示层 提供数据格式转换、数据加密、数据压缩等功能。
- 应用层 为应用程序提高网络服务。
TCP/IP四层模型:
- 网络接口层 物理层、数据链路层的合并。
- 网际层 网络层。
- 传输层 传输层。
- 应用层:会话层、表示层、应用层的合并。
而五层原理模型是在TCP/IP模型的基础上,将物理层、数据链路层分开,便于理解和学习。
术语
- 实体 任何可发送和接收信息的硬件或软件进程。
- 对等实体 相同层次中的实体。
- 协议 控制两个对等实体进行逻辑通信的规则集合。
协议的三要素:
- 语法 定义所交换信息的格式
- 语义 定义收发双方要完成的操作。
- 时序 定义操作的时序关系。
服务:
- 本层使用下层的服务,实现本层的协议,并完成对等实体的逻辑通信。
- 在协议的控制下,两个对等实体进行逻辑通信,使得本层能够向上层提供服务。
- 协议是水平的,而服务是垂直的。
- 实体能使用相邻下层提供的服务,但不知道实现服务的具体协议,下层的协议对上层是透明的。
- 服务访问点 在同一系统中相邻两层的实体交换信息的逻辑接口,用于区分不同的服务类型。
- 服务原语 上层使用下层服务的方式(需要交换的命令)。
- 服务数据单元SDU 服务访问点之间交换的数据包。
- 协议数据单元PDU 对等实体之间交换的数据包。
五层原理模型
物理层:
- 数据包: 比特流
- 协议任务:规定传输媒体的机械、电气、功能和过程特性。
- 考虑如何在连接各种设备的物理传输媒介上传输数据(比特流)。
- 为数据链路层屏蔽了各种物理传输媒介的差异,使链路层只需考虑如何完成自己的协议和服务,而不必考虑网络的物理细节。
数据链路层:
- 数据包:帧
- 服务访问点:帧的类型字段
- 封装成帧:将网络层的数据包封装成帧,添加帧头和帧尾。
- 透明传输:对网络层交付的数据没有限制,就好像链路层不存在一样。通过比特填充或字符填充实现。
- 差错检测:使用差错检测码,通过奇偶校验、CRC循环冗余校验等方法检测数据的比特差错。
- 可靠传输:检测到误码后,不可靠传输直接丢弃有误码的帧,可靠传输则想办法实现接收到的数据与发送的数据一致。如停止等待协议SW、回退N帧协议GBN、选择重传协议SR。
- 有线链路误码率较低,一般不要求链路层提供可靠传输服务,即使有误码也由上层进行处理。而无线链路易受干扰,误码率较高,所以链路层必须提供可靠传输服务。
- 可靠传输并不只在链路层实现,各层都有不同的传输差错,如分组丢失、分组重复、报文段丢失等,各层都可以根据应用需求,选择提供可靠传输服务。
- 点对点PPP协议 实现了透明传输、差错检测、向上提供不可靠传输服务。
- 媒体接入控制MAC 信道复用、CSMA/CD(多址接入、载波监听、碰撞检测)
- MAC地址:每个主机(接口)的唯一标识,一般被固化在网卡(网络适配器)上,也称为硬件地址。
网络层:
- 数据包:IP数据报或分组
- 服务访问点:IP数据报首部的协议字段
- 路由选择:选择合适的路径,将数据包从源主机传输到目的主机。
- 分组转发:将数据包从一个网络节点传输到另一个网络节点。
- IP地址:每个主机和路由器的唯一标识,由网络号和主机号组成。
- 子网掩码:用于划分网络号和主机号。
- 路由器:实现了网络层的功能,负责转发数据包,选择合适的路径,拥塞控制等。
- ARP地址解析协议:将IP地址解析为MAC地址。
传输层:
- 数据包:TCP报文段或UDP用户数据报
- 服务访问点:端口号
- 面向通信的最高层,面向用户功能的最低层。
- 为运行在不同主机上的应用进程提供端到端的逻辑通信。
- 端口:通过端口号来区分不同的应用进程。将数据包交付给正确的应用进程。
- TCP 提供可靠的、面向连接的、字节流的通信服务。
- UDP 提供不可靠的、无连接的、数据报的通信服务。
- 拥塞控制:TCP通过滑动窗口、超时重传、拥塞窗口、慢开始和拥塞避免、快重传和快恢复。
应用层:
- 数据包:报文
- DHCP动态主机配置协议:为主机分配IP地址。基于UDP。
- ICMP网际控制报文协议:报文发送出错的处理。终点不可达、超时、源点抑制等。
- 客户/服务器模型:客户端向服务器请求服务,服务器向客户端提供服务。
- P2P模型:网络中的每个主机既是客户端也是服务器。数据不再存储在中心服务器上。
- DNS域名系统:将域名解析为IP地址。
- FTP文件传输协议:文件传输。
- 电子邮件:SMTP、POP3、IMAP。
- WWW万维网:基于HTTP协议的分布式信息系统。由URL(统一资源定位符)对资源定位,这些资源通过HTTP协议传输。
- HTTP超文本传输协议:使用TCP协议进行可靠传输。
TCP
传输控制协议(Transmission Control Protocol,简称 TCP)是一种 面向连接(连接导向)的、可靠的、 基于 IP 协议的传输层协议。
- 面向连接:每条 TCP 连接只能有两个端点(亦即点对点,不可广播、多播),每一条 TCP 连接只能是一对一。
- 可靠的传输服务:通过 TCP 连接传送的数据,无差错、不丢失、不重复、并且按序到达,丢包时通过重传机制进而增加时延实现可靠性。
- 全双工通信:TCP 允许通信双方的应用进程在任何时候都能发送数据。TCP 连接的两端都设有发送缓存和接收缓存,用来临时存放双方通信的数据。
- 字节流:面向字节流,TCP 中的 流(Stream)指的是流入进程或从进程流出的字节序列。
- 流量缓冲:解决速度不匹配问题。
数据包结构:
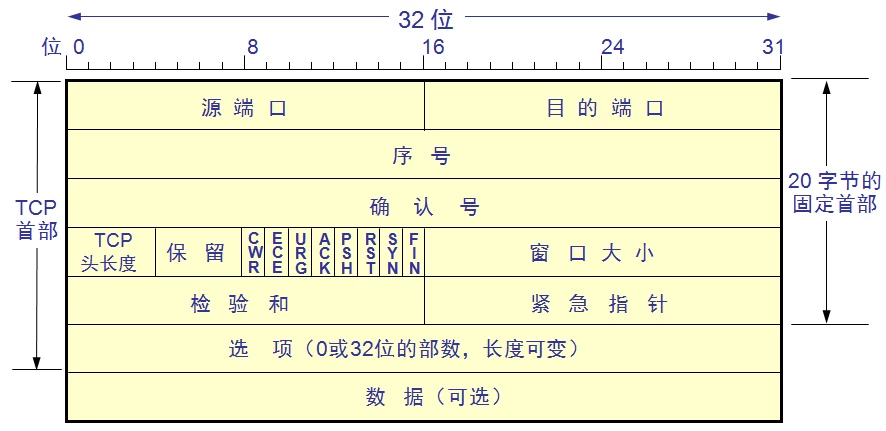
TCP 首部标志比特有 6 个:URG、ACK、PSH、RST、SYN、FIN
| 控制位 | 名称 | 说明 |
|---|---|---|
| URG | Urgent Flag | 紧急指针 |
| ACK | Acknowledge Flag | 确认序号有效 |
| PSH | Push Flag | 尽可能快地将数据送往接收进程 |
| RST | Reset Flag | 可能需要重现创建建 TCP 连接 |
| SYN | Synchronize | 同步序号来发起一个连接 |
| FIN | Finish | 发送方完成发送任务,要求释放连接 |
两个32位号:
- Seq(Sequance number) 序列号,是上次已成功发送的序号+1。
- Ack() 确认序号,让发送方(对方)下一次发送的序号,即接收方下一次期望收到的序号。
三次握手
TCP 提供面向连接的通信传输,无论哪一方向另一方发送数据之前,都必须先在双方之间建立一条连接。三次握手是指建立一个 TCP 连接时需要客户端和服务器端总共发送三个包以确认连接的建立。
目的:
- 同步连接双方的 Sequence 序列号和确认号。
- 交换 TCP 窗口大小信息,如 MSS、窗口比例因子、选择性确认、指定校验和算法。
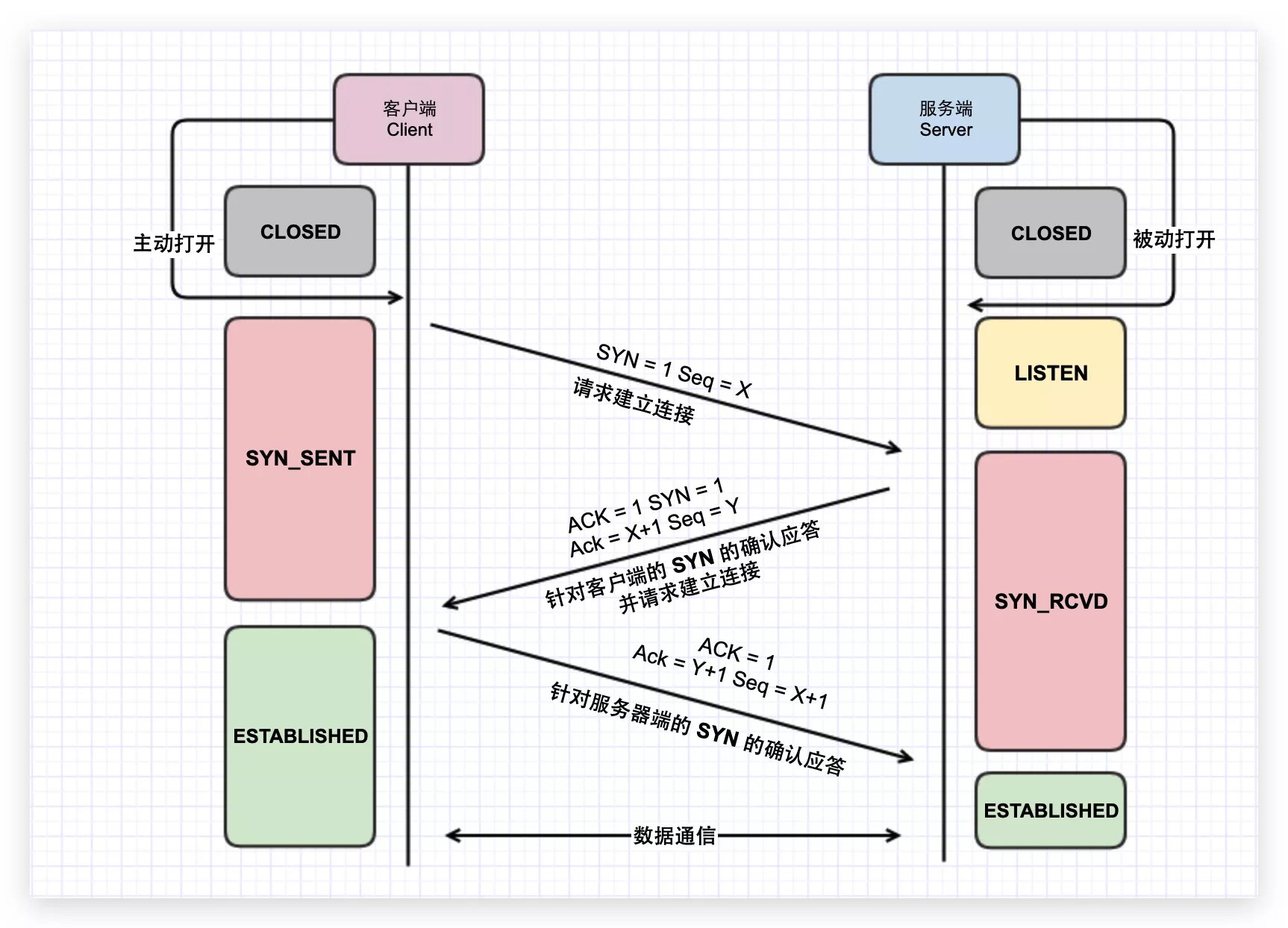
握手过程中传送的包里不包含数据,但第三次握手可以发送数据。
四次挥手
断开一个 TCP 连接时,需要客户端和服务端总共发送 4 个包以确认连接的断开。
由于 TCP 连接是全双工的,因此,每个方向都必须要单独进行关闭,
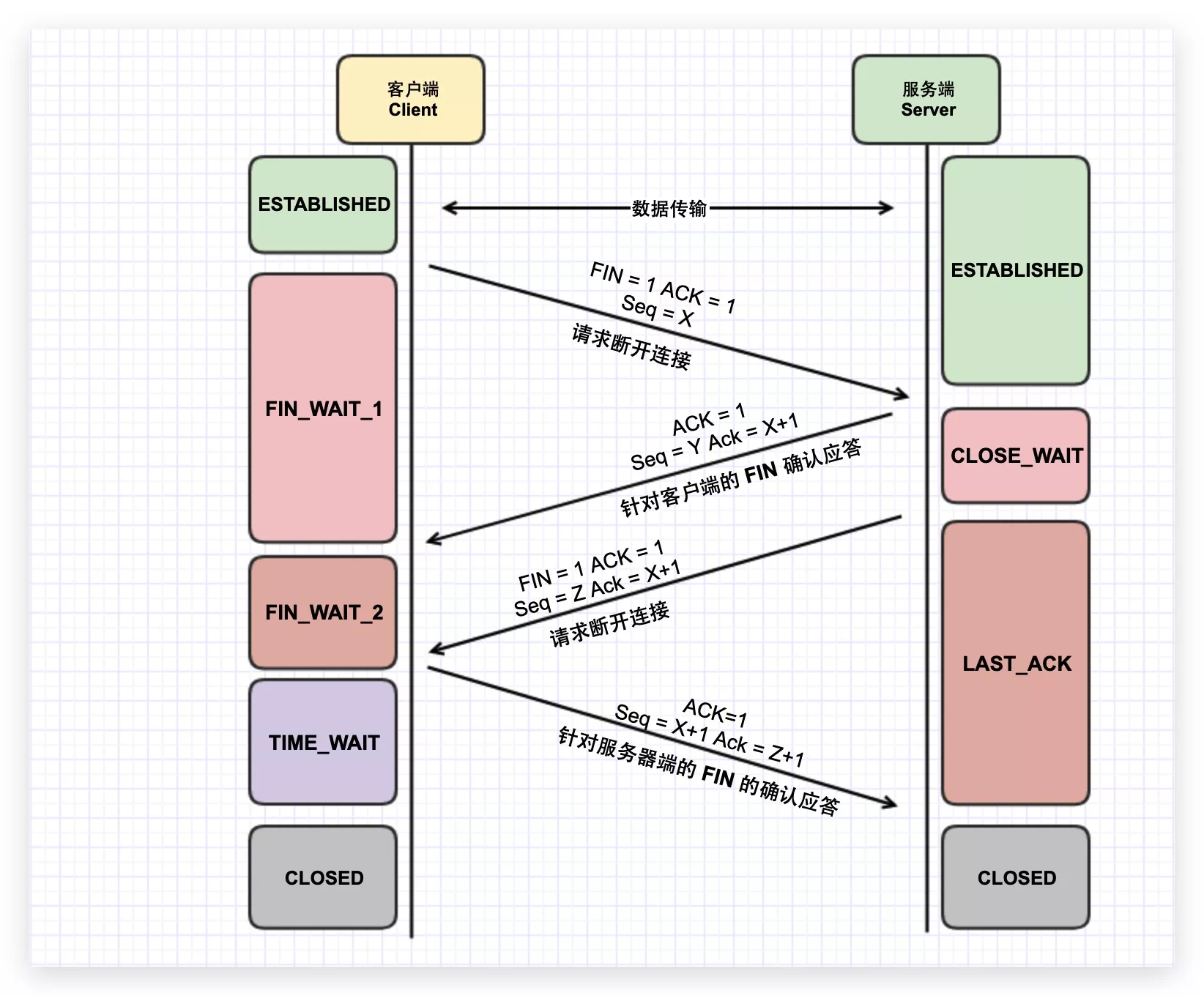
在客户端发送最后一个ACK包后,会进入 TIME_WAIT 超时等待状态,通常持续1-4分钟,这是为了实现可靠、稳定的传输,若该ACK包丢失了,服务端会超时重发FIN包,客户端接收到重发的FIN包后,重新发送ACK包。
输入url后
浏览器输入url后:
- 解析URL 解析出协议、域名、端口、资源路径、参数等。
- [查询缓存] 如果HTTP缓存命中,则直接返回缓存资源。详见:浏览器HTTP缓存
- DNS解析 若域名部分是一个主机名,则通过DNS将域名转换为IP地址。
- 建立TCP连接 三次握手。
- [SSL/TLS] 如果是 HTTPS 协议,还需要进行 SSL/TLS 握手过程,以协商出一个会话密钥,用于消息加密,提升安全性。
- 发送HTTP请求 HTTP请求中包含了浏览器需要获取的资源的相关信息,如请求的方法、资源的路径、查询参数、请求头部信息等。服务器收到HTTP请求后,会根据请求的内容进行处理,并返回相应的HTTP响应。
- 接收服务器响应 获取页面所需的各种资源。
- 页面渲染 将静态资源转为可视、可交互的页面,详见:浏览器渲染流程。
- 断开TCP连接 四次挥手。
DNS解析
域名具有分层结构,以 www.baidu.com 为例
com是顶级域名baidu.com是主域名、一级域名www.baidu.com是子域名、二级域名
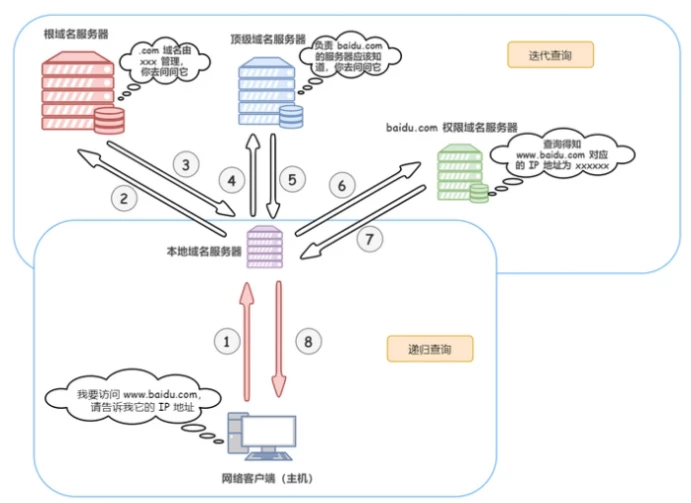
DNS 域名解析系统(Domain Name System)是将域名转换为IP地址的服务器。
DNS 服务器也具有对应的层级结构,每个层的域名上都有自己的域名服务器,最顶层的是根域名服务器。
- 本地域名服务器 DNS Resolver 或 Local DNS。本地域名服务器是响应来自客户端的递归请求,并最终跟踪直到获取到解析结果的 DNS 服务器。例如用户本机自动分配的 DNS、运营商 ISP 分配的 DNS、谷歌/114 公共 DNS 等。
- 根域名服务器 Root NameServer,本地域名服务器在本地查询不到解析结果时,则第一步会向它进行查询,并获取顶级域名服务器的 IP 地址。
- 顶级域名服务器 TLD(Top-level)NameServer。负责管理在该顶级域名服务器下注册的一级域名。例如 www.example.com、.com 则是顶级域名服务器,在向它查询时,可以返回一级域名 example.com 所在的权威域名服务器地址。
- 权威域名服务器 Authoritative NameServer。在特定区域内具有唯一性,负责维护该区域内的域名与 IP 地址之间的对应关系,例如云解析 DNS。
DNS解析过程:
- 查询浏览器自身DNS。
- 操作系统DNS。
- 本地 hosts 文件。
- 向域名服务器发送请求。
DNS查询方式:
- 递归查询 如果主机所询问的本地域名服务器不知道被查询域名的 IP 地址,那么本地域名服务器就以 DNS 客户端的身份,向其他根域名服务器继续发出查询请求报文,即替主机继续查询,而不是让主机自己进行下一步查询。
- 迭代查询 当根域名服务器收到本地域名服务器发出的迭代查询请求报文时,要么给出所要查询的IP 地址,要么告诉本地服务器下一步应该找哪个域名服务器进行查询,然后让本地服务器进行后续的查询。
通常客户端与本地域名服务器之间是递归查询,而本地域名服务器与其它层级之间是迭代查询。
跨域
老生常谈的跨域问题,是由于浏览器的同源策略导致的。
详见:
AJAX请求相关-跨域
Node-回眸[三]-CORS
跨源资源共享(CORS)-MDN
跨域资源共享 CORS 详解-阮一峰
同源策略:协议、域名、端口 三者相同,即为同源,否则为跨域。
解决跨域问题:
- fetch 设置 no-cors 模式,在该模式下,浏览器不会将Origin包含在请求偷中,并且服务器的响应是不透明的,JS无法获取响应内容。此模式适用于不需要服务器响应的情况,例如向第三方分析服务发出请求。
1
2
3
4
5
6
7fetch('https://share.qcqx.cn/', {
mode: 'no-cors' ,
method: 'GET',
})
.then(response => response.json())
.then(data => console.log(data))
.catch(error => console.error(error)) - JSONP 利用 script 标签的 src 属性不受同源策略限制的特点,通过动态创建 script 标签,将请求的数据作为查询参数,服务器返回的数据会被当做 JS 代码执行(通常是调用一个函数,将数据作为该函数的参数)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22function jsonp(url, name) {
const script = document.createElement('script');
script.src = url + '?callback=' + name;
document.body.appendChild(script);
return new Promise((resolve, reject) => {
// 全局记录回调函数,服务器返回的数据会被当做 JS 代码执行,即执行回调函数
window[name] = data => {
resolve(data);
document.body.removeChild(script);
}
})
}
jsonp('https://share.qcqx.cn/', 'callback').then(console.log);
// 后端部分
const data = {
name: 'chuckle'
}
app.all('/test', (req,res)=>{
const { callback } = req.query;
// 返回数据,即执行回调函数,将数据作为参数
res.end(`callback(${data.name})`);
}) - CORS(Cross-Origin Resource Sharing)跨源资源共享,服务器端设置响应头,以允许跨域请求。通常还需要设置允许的请求头、请求方式、是否携带cookie等。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28// 请求来源白名单
const allowedOrigins = ["127.0.0.1:5500", undefined];
app.use((req, res, next) => {
const origin = req.headers.origin;
// 判断请求来源是否在白名单内
if (
(origin && allowedOrigins.some((item) => origin.includes(item))) ||
allowedOrigins.includes(origin)
) {
// 设置允许跨域的域名,*代表允许任意域名跨域
res.header('Access-Control-Allow-Origin', origin);
// 允许的header类型,如下设置允许自定义header、允许Content-Type为非默认值等,按需删改
res.header('Access-Control-Allow-Headers', "*, Origin, X-Requested-With, Content-Type, Accept, Authorization");
// 跨域允许的请求方式
res.header('Access-Control-Allow-Methods', 'PUT, POST, GET, DELETE, PATCH ,OPTIONS');
// 跨域的时候是否携带cookie
// 需要与 XMLHttpRequest.withCredentials 或 Fetch API 的 Request() 构造函数中的 credentials 选项结合使用
res.header("Access-Control-Allow-Credentials", true);
if (req.method.toLowerCase() == 'options') {
res.send(200); // 让options请求快速结束
}
else {
next();
}
} else {
res.status(403).send('Forbidden');
}
}) - 本地代理:webpack、vite等构建工具都提供了代理配置,将请求代理到本地服务器,再由本地服务器请求真实数据,从而避免跨域问题。只能用于开发环境。
- nginx 代理,将请求代理到后端服务器,避免跨域。适合生产环境。
ajax相关
详见:AJAX请求相关
SSE
WebSocket
JWT
JWT-JSON Web Token 用于会话控制、用户认证,无状态,通常无需服务端存储。
JWT 以 JSON 对象的形式安全地传输信息。该信息可以被验证和信任,因为它是经过数字签名的。
JWT 由三部分组成,使用 Base64 编码,以点号分隔:
- Header 头部,包含了两部分:token 的类型(即 JWT)和使用的加密算法(如 HMAC SHA256 或 RSA)。
- Payload 负载,包含了要传递的信息,如用户 ID、用户名等。
- Signature 签名,由头部、负载、密钥、加密算法生成,用于验证消息的完整性、防止篡改。
可以使用 jwt.io 调试器、jwt解密/加密 在线验证和生成 JWT。
Payload 预先定义了7个标准字段,这些字段是推荐的,但不是必须的:
- iss (issuer):签发者
- sub (subject):主题
- aud (audience):受众
- exp (expiration time):过期时间
- nbf (Not Before):生效时间
- iat (Issued At):签发时间
- jti (JWT ID):编号
签名:
JWT 会使用头部中指定的加密算法(如 HS256)对头部和负载进行签名,作为 Signature 部分。
签名只是用于验证 token 的完整性,在使用密钥加密后可进行验证,防止篡改。
校验过程:使用相同的密钥和算法对头部和负载进行签名,然后与接收到的签名进行比较,若一致则验证通过。
1 | HMACSHA256( |
负载半身并不加密,只是 Base64 编码,所以不要在 JWT 中存储敏感信息,如密码等。
jwt 通常放在请求头的 Authorization 字段中:
1 | Authorization: Bearer <token> |
在 Node 和 Nest 中使用 JWT,详见:
NodeJS接口、会话控制#token
NestJS[三]-进阶#JWT-token
前端网络状态
navigator.onLine 返回一个布尔值,表示用户的设备是否与网络连接,即是否在线。
window 的两个事件:
- online 从离线状态变为在线状态时触发。
- offline 从在线状态变为离线状态时触发。
1 | window.addEventListener('online', () => { |
区分强弱网络环境:navigator.connection 返回 NetworkInformation 对象,包含了用户设备的网络信息。
1 | { |
XSS
XSS 跨站脚本攻击(Cross-Site Scripting)
方式:在目标网站 HTML 页面中注入恶意脚本,并使之执行,从而获取用户 cookie、token 等敏感信息。
本质:恶意代码未经过滤,与网站正常的代码混在一起,被浏览器执行。
可分为三种类型
- 反射型 将恶意脚本放在 URL 中,通常需要用户手动点击。
- 存储型 将恶意脚本存储在数据库中。最严重。
- DOM型 修改页面的DOM节点,将恶意脚本插入到页面中。
实际上几种类型通常是混合使用的。最后总是要通过漏洞将恶意脚本插入到页面中执行。
一个XSS靶场:xssaq
例子:
1 | <textarea id="input"></textarea> |
用户输入的内容未经过滤就插入到页面中。有效载荷(Payload):
1 | <script>alert(document.cookie)</script> |
常见攻击漏洞:
- 未过滤的用户输入 如上例,常见于评论、搜索等,innerHTML 会将输入的内容解析为 HTML。
- 标签拼接漏洞 常见于后端模板渲染时,未进行 HTML 实体字符转义。
- 提前闭合标签 对于 input、textarea 等原生会将输入数据转为字符串的标签,可以通过提前闭合标签绕过。
- 0级事件注入,如
onerror、onload、onclick等。 - 在标签的 href、src 等属性中,包含
javascript:等可执行代码
1 | // 提前闭合标签 |
现代化的浏览器通常已经对 XSS 的代码注入进行了一定的防护。HTML5 也规定了不执行由 innerHTML 插入的 script 标签。
防护手段
- 转义字符 将特殊字符转义为 HTML 实体字符,如
<转为<。 - 对
javascript:进行过滤。 - Cookie 开启
HttpOnly,防止 JS 访问。 - CSP Content-Security-Policy 内容安全策略,限制页面加载的资源。
1 | root.innerHTML = input.value.replace(/</g, '<').replace(/>/g, '>'); |
实际生产中,应使用成熟的 XSS 防护库,如:xss
CSP 内容安全策略
CSP 内容安全策略(Content Security Policy) 约束可信内容来源,是一种白名单机制,用于削弱某些特定类型的攻击,包括跨站脚本 (XSS) 和数据注入攻击等。
两种配置方式:
- HTTP 头部 设置
Content-Security-PolicyHTTP 头部。 - meta 标签 添加
<meta http-equiv="Content-Security-Policy" content="...">。
content 为规则,包括指令(限制选项)与值,多个值使用空格分割,指令之间用分号分隔。如果同一个限制选项使用多次,只有首个会生效。
1 | Content-Security-Policy: script-src 'self'; object-src 'none'; style-src cdn.example.org third-party.org; child-src https: |
启用后,不符合 CSP 规则的外部资源就会被阻止加载。
限制选项
CSP 提供了很多限制选项,涉及安全的各个方面。
资源加载限制:
script-src:用于控制脚本资源的加载和执行。style-src:会控制样式表@import和rel时所引入的 URI 资源,设置unsafe-inline规则可以是浏览器拒绝解析内部样式和内联样式定义。并不会阻止链入外部样式表。img-src:可以控制图片资源的连接,包括 img 标签的 src 属性,以及 CSS3 中的url()和image()方法,以及 link 标签中的 href 属性(当 rel 设置成与图像相关的值,比如 HTML 支持的 icon)font-src:控制 CSS 中的 @font-face 加载的字体源地址frame-src:设置允许通过类似<frame>和<iframe>标签加载的内嵌内容的源地址manifest-src:限制应用声明文件的源地址media-src:控制媒体类型的外部链入资源,如<audio>、<video>、<source>和<track>标签的 src 属性object-src:控制<embed>、<code>、<archive>、<applet>等对象prefetch-src:指定预加载或预渲染的允许源地址connect-src:控制 XMLHttpRequest 中的open()、WebSocket、EventSource
default-src 是一个通用的资源加载限制选项,可以作为其他限制选项的默认值。其它选项的值会覆盖默认值。
URL 限制:
frame-ancestors:限制嵌入框架的网页base-uri:限制<base#href>form-action:限制<form#action>
其他限制:
block-all-mixed-content:HTTPS 网页不得加载 HTTP 资源(浏览器已经默认开启)upgrade-insecure-requests:自动将网页上所有加载外部资源的 HTTP 链接换成 HTTPS 协议plugin-types:限制可以使用的插件格式sandbox:浏览器行为的限制,比如不能有弹出窗口等。report-uri向指定url上报违反 CSP 的行为,POST 请求,包含 JSON 数据。仅在使用 HTTP 头部时有效。
选项值
'none':禁止加载任何外部资源'self':只允许加载同源资源- 主机名:example.org,https://example.com
- 路径名:example.org/resources/js/
- 通配符:*.example.org,*://*.example.com:*(表示任意协议、任意子域名、任意端口)
- 协议名:https:、data:,注意末尾的冒号
script-src
script-src 控制脚本资源的加载和执行,具有一些额外的特殊值
unsafe-inline:允许执行页面内嵌的<script>标签和事件监听属性,如onclick、onerror等。unsafe-eval:允许将字符串当作代码执行,比如使用eval、setTimeout、setInterval和Function等函数。nonce-值:每次HTTP回应给出一个授权token,页面内嵌脚本必须有这个token,才会执行hash-值:列出允许执行的脚本代码的Hash值,页面内嵌脚本的哈希值只有吻合的情况下,才能执行。
nonce值:
1 | Content-Security-Policy: script-src 'nonce-EDNnf03nceIOfn39fn3e9h3' |
hash值:
1 | Content-Security-Policy: script-src 'sha256-qznLcsROx4GACP2dm0UCKCzCG-HiZ1guq6ZZDob_Tng=' |
style-src 也具有类似的特殊值,如 unsafe-inline、nonce-值、hash-值。
HTTP
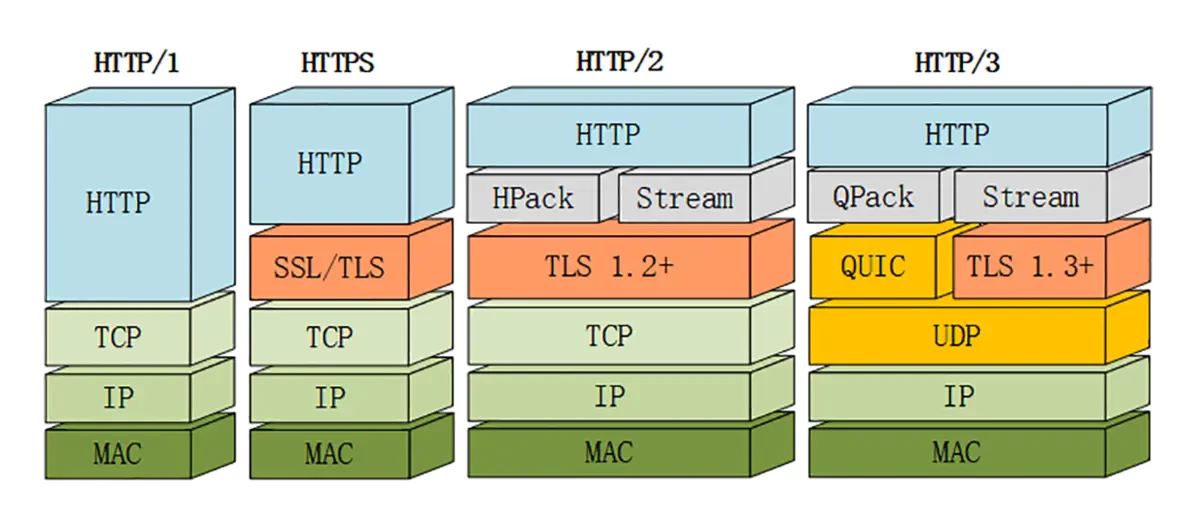
HTTP(HyperText Transfer Protocol)超文本传输协议,基于请求/响应模型、无状态的应用层协议。
- HTTP/0.9 - 1991 单行协议:只支持 GET 方法;没有首部;只能获取纯文本
- HTTP/1.0 - 1996 搭建协议框架:增加了首部、状态码、权限、缓存、长连接(默认短连接)等规范
- HTTP/1.1 - 1997 默认长连接;缓存字段扩展;强制客户端提供 Host 首部;管线化
- SPDY - 2012 强制压缩、多路复用、Pipeling、双向通信、优先级调用
- HTTP/2 - 2015 头部压缩、多路复用、Pipelining、Server push(解决 HTTP 队头阻塞)
- HTTP/3 - 2018 基于QUIC(UDP),快速握手、可靠传输、有序交付(解决 TCP 队头阻塞)
参考:
关于队头阻塞(Head-of-Line blocking),看这一篇就足够了
面试官:说说 HTTP1.0/1.1/2.0 的区别?
HTTP发展史(HTTP1.1,HTTPS,SPDY,HTTP2.0,QUIC,HTTP3.0)
JavaScript Guidebook-HTTP
HTTP2基本概念学习笔记
HTTP 协议入门-阮一峰
HTTP/2 服务器推送(Server Push)教程-阮一峰
HTTP/3 原理实战
深入剖析HTTP3协议
QUIC核心原理和握手过程
QUIC 握手流程梳理
HTTP消息
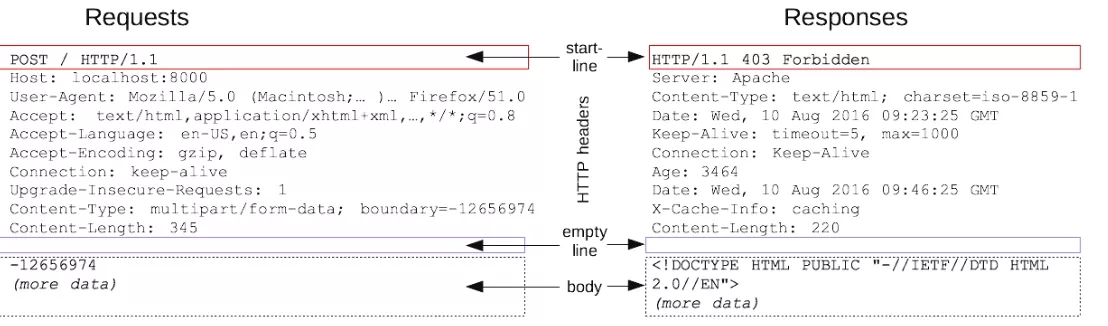
HTTP 消息是服务器和客户端之间交换数据的方式,分为请求和响应。
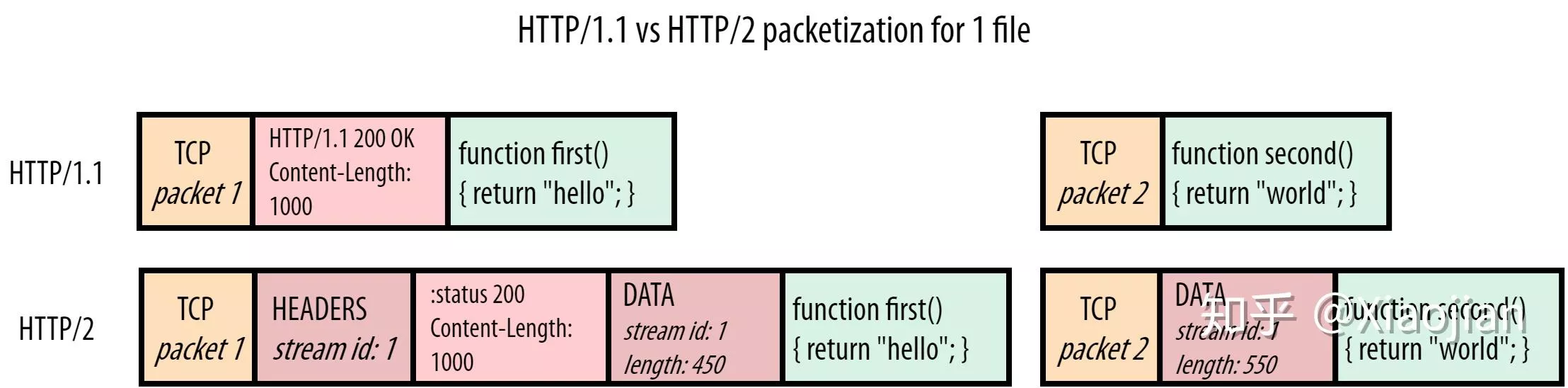
HTTP 消息由采用 ASCII 编码的多行文本构成。在 HTTP/1.1 及早期版本中,这些消息通过连接公开地发送。在 HTTP/2 中,为了优化和性能方面的改进,曾经可人工阅读的消息被分到多个 HTTP 帧中。
消息结构:
- 起始行 包括请求方法、请求目(url)、HTTP版本、状态码、状态描述短语
- HTTP标头 用于描述报文
- 空行 用于分隔头部和主体,表示消息的元数据部分结束
- 消息主体 可选,包含任意数据,如文件、图片、表单数据等
HTTP1.0
HTTP1.0 是第一个被广泛使用的版本,它是一个简单的请求/响应协议,每个请求都会建立一个新的TCP连接。
在 HTTP1.0 中认为每台服务器都绑定一个唯一的IP地址,因此,请求头部中没有 Host 字段。但随着虚拟主机技术的发展,一台物理服务器上可以运行多个虚拟主机共享同一个IP,因此需要在请求头部中加入 Host 字段。
缺点:
- 连接频繁的建立和断开会消耗时间和资源。
- 无法充分利用带宽,TCP协议特点是慢启动,即一开始传输的数据量小,然后逐渐增大,而短连接导致每次都要重新慢启动,难以达到峰值。
- 队头阻塞,同一个域名下的请求会排队等待,需要等待前一个请求完成并断开后才能继续请求下一个资源。
HTTP1.1
1、长连接(持久连接):MDN
HTTP1.1默认开启长连接,即默认带上 Connection: keep-alive 头部。
长连接可以让多个请求和响应复用同一个 TCP 连接进行串行请求,减少了建立和断开TCP连接的开销,提高了传输效率。
但仍然存在队头阻塞问题,后面的请求必须等待前面的请求完成后才能进行。
2、流水线Pipelining(管线化):MDN
HTTP1.1 支持流水线,即支持请求并发,不用等待上一次请求结果返回,可以直接发出下一次请求。
但响应必须按照请求的顺序返回,队头阻塞仍然可能发生,如果前一个请求非常耗时甚至超时,那么后续请求的响应仍然会受到影响。
管线化只解决了请求的队头阻塞问题,但是响应的队头阻塞问题仍然存在,且web的性能问题大多数是由于响应的队头阻塞问题导致的。
现代浏览器中,流水线是禁用的,HTTP1.1传输的信息是文本,且没有逻辑流概念,实现流水线非常复杂,让并发的请求和响应一一对应也是困难的,反而会造成更多问题。
已被 HTTP/2 中的多路复用(multiplexing)所取代。
3、增加更多的请求头和响应头来完善的功能:
- Host:指定服务器的域名和端口号。所有 HTTP/1.1 请求报文中必须包含一个Host头字段。
- 引入range,允许只请求资源某个部分。
- 引入了更多的缓存控制策略,如If-Unmodified-Since, If-Match, If-None-Match等缓存头来控制缓存策略。
4、多TCP连接:MDN
单个TCP连接仍然有队头阻塞问题。因此HTTP1.1允许为每个域名建立多个TCP连接,通常为6个,一个请求选择一个连接发送后就不能再换用其它连接。
域名分片:将资源分散到指向同一个服务器的不同的域名下,以便绕过TCP最大连接限制,提高并发请求的数量。这是一个过时的技术,但仍然广泛使用。
队头阻塞的根本原因:http1.1是基于文本的协议,文本是不能分割、乱序传输(乱序封装为TCP报文)的,后续将TCP报文按顺序组装成HTTP报文后,文本就错乱了。所以,一个连接中请求响应必须按顺序完成。
HTTP2
旧版本问题:
- 多个 TCP 连接:虽然 HTTP/1.1 管线化可以支持请求并发,但是浏览器很难实现,主流浏览器厂商都禁用了管线化
- 队头阻塞:TCP 连接上只能发送一个请求,由于单连接上的串行请求,前面的请求未完成前,后续的请求都在排队等待
- 头部冗余:HTTP/1.x 采用文本格式传输,首部未压缩,无状态特性让每个请求都会带上 Cookie、User-Agent 等重复的信息
- 不支持服务端推送:HTTP/1.1 不支持服务推送消息,只能使用轮询的方式解决
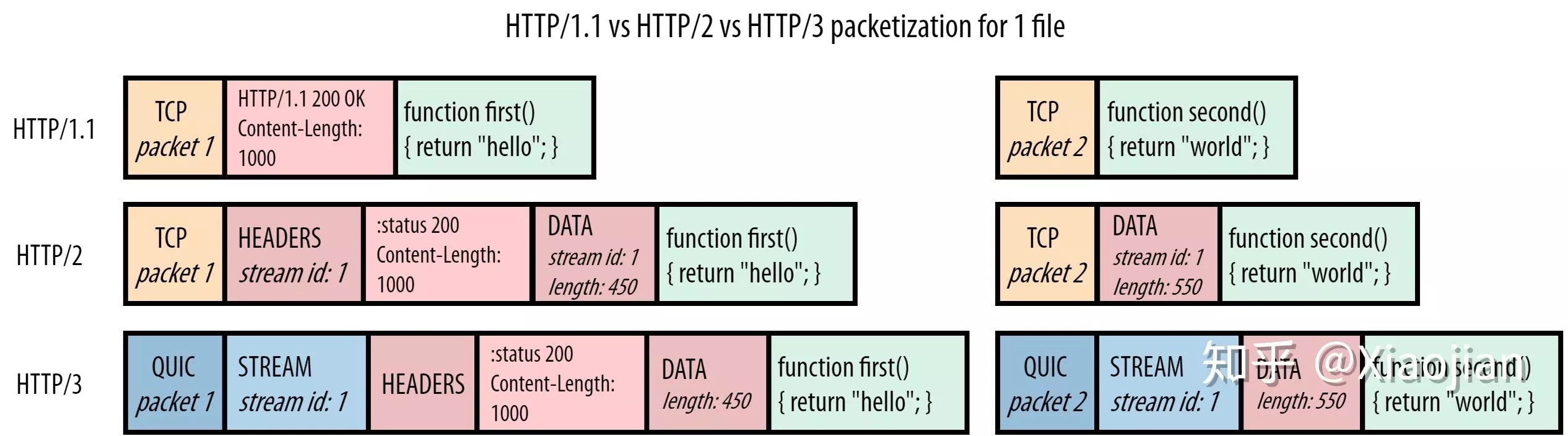
HTTP2 引入了二进制分帧层,将 HTTP 消息分割为更小的消息和帧,每个帧都是一个二进制块,可以乱序发送,然后在接收端重新组装。
二进制分帧
HTTP帧:HTTP2 通信的最小单位,每个帧包含帧头部(固定9字节),用于描述帧的流ID、有效载荷的长度、类型等信息。并且将头部和主体分别封装为头部帧(HEADERS frame)和数据帧(DATA frame)。
消息: 与逻辑请求或响应消息对应的完整的一系列帧。
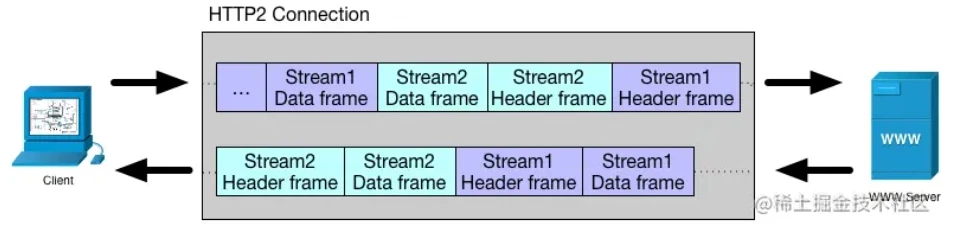
逻辑数据流:一个虚拟的连接,可以承载双向消息,每个数据流都有一个唯一的标识符。
流ID: 位于帧头,标识出当前帧所属的数据流,接收数据时根据流ID将帧重新组装为完整的消息。
逻辑上多个流在一个 TCP 连接上并行传输,实际上,各个流的各个帧混合封装为多个TCP报文按顺序进行传输。
多路复用 MultiPlexing
允许多个消息同时在单个 TCP 连接上传输,并且不会阻塞或等待其他消息的响应,解决了 HTTP/1.x 的队头阻塞问题。
支持流的优先级(Stream dependencies)设置,允许客户端告知服务器最优资源,可以优先传输。
核心概念:将 HTTP 消息分解为独立的帧,交错发送,然后在另一端重新组装。
有了二进制分帧后,不再依赖多 TCP 链接、域名分片去实现多流并行,而是通过逻辑数据流支持多路复用。
标头压缩
在 HTTP/1.x 中,标头元数据以纯文本形式传输,带来额外的空间开销。HTTP/2 使用 HPACK 霍夫曼编码压缩请求和响应标头元数据,减少冗余数据,降低开销。
做法:
通过HPACK对传输的标头字段进行编码,从而减小了消息的大小。
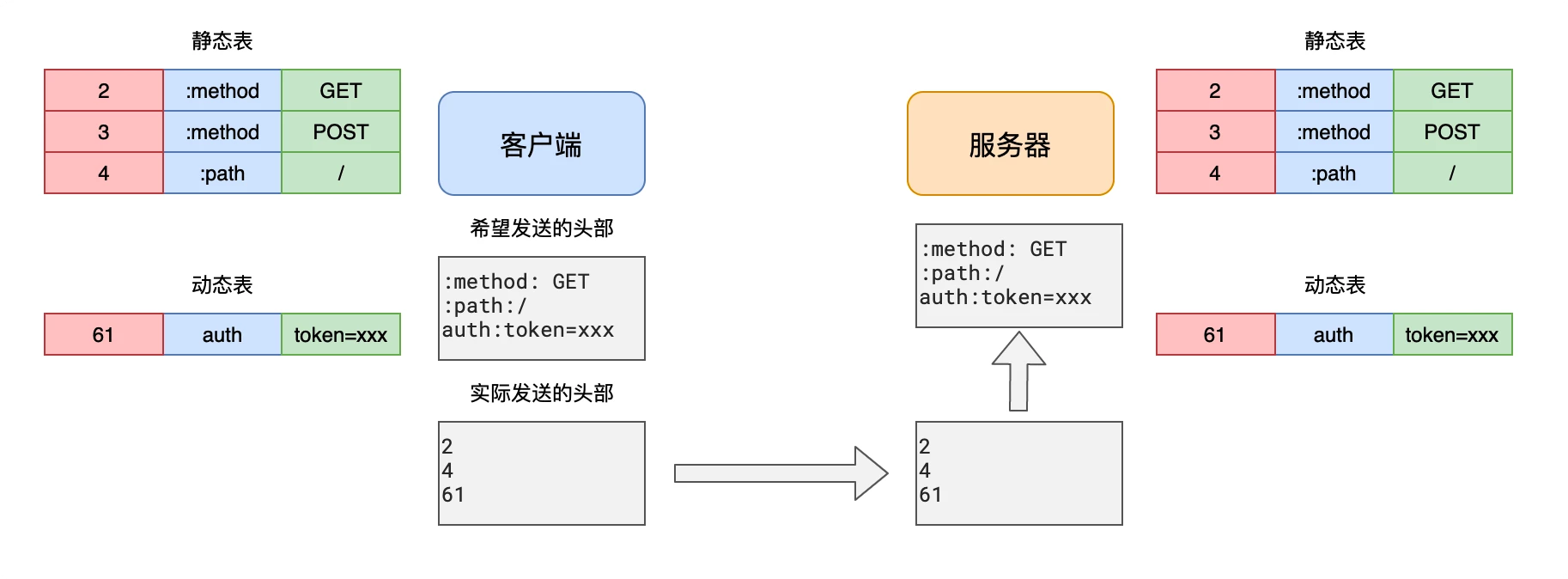
要求通讯双方各自维护一份头域索引表(首部表),相同的消息头部字段只发送索引号,此索引表随后会用作参考,对之前传输的值进行有效编码。
关于 HPACK 头部压缩标准 的制定
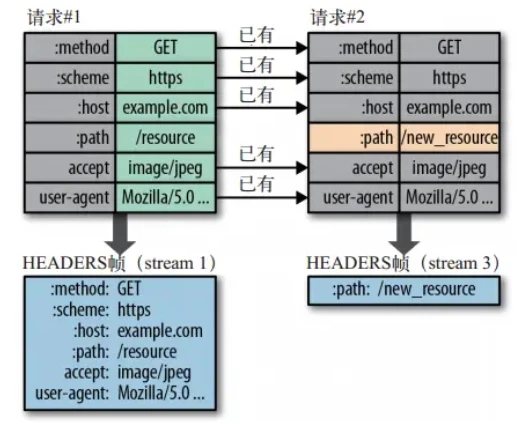
索引表又分为静态表和动态表,静态表包含常见的标头字段,动态表包含最近发送的其它标头字段。
- 静态表是固定的,根据主流网站最常用的标头字段创建,并添加了 HTTP/2 特定的伪标头字段(以冒号开头),详见RFC 7541#HPACK: Header Compression for HTTP/2
- 动态表一开始是空的,随着通信的进行,会不断添加新的标头字段,以便在后续的通信中复用,通常是一些自定义的标头字段。
HTTP2 中请求行独立为了 :method、:scheme、:authority、:path 等键值对
1 | :authority: img.alicdn.com |
服务器推送 Server Push
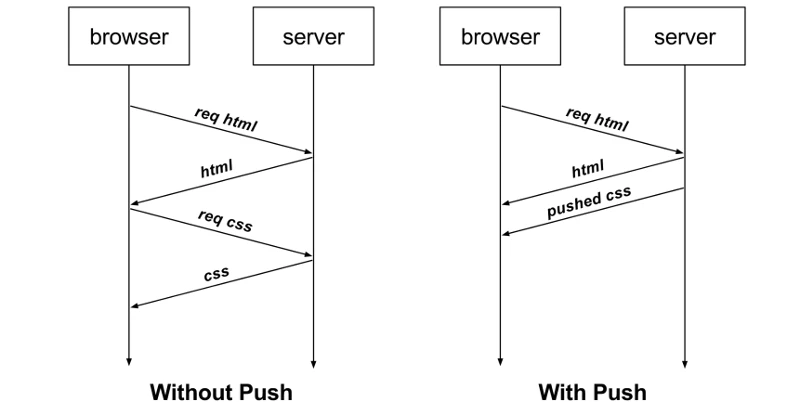
HTTP2 的服务器推送用于提前将资源推送至浏览器缓存。
并不是类似于现在的 SSE 或者 WebSocket 的推送技术。它是一种服务器根据客户端以前发送的请求来猜测未来的请求,并提前将未来请求的结果推送给客户端的技术。
HTTP3
HTTP/2 只解决了应用层 HTTP 的队头阻塞,但传输层 TCP 仍然存在队头阻塞问题,因为 TCP 是面向流的,一个数据包丢失,后续的数据包都要等待重传,导致队头阻塞。
TCP 层队头阻塞(由于丢失或延迟的数据包)也会最终导致 HTTP 队头阻塞
HTTP/2 将多个消息分解为多个帧,若干个帧合并作为TCP报文的载荷,在一个TCP连接上传输,但 TCP 不知道 HTTP 流的,只将所有上层交付的数据作为一个大流,TCP 为了实现可靠传输,会对数据包的丢失进行等待重传,后续的TCP报文到达后只能进入缓存,需等待重传完成后才能继续操作,即使缓存中数据包内负载的帧已经能重新组装成完整的消息和资源。
实际上,在TCP的拥塞控制机制下,单个连接上的 HTTP/2 并没有比6个TCP连接上的 HTTP/1.1 快多少,在数据包丢失率较高的低速网络上可能更慢,因此浏览器仍然可能为同一域名打开多个并行的 HTTP/2 连接。
总之,TCP 并不能完美适配 HTTP/2 的多路复用,两者的流概念存在冲突,因此 HTTP/3 诞生了。
QUIC的多路复用
Google 在推 SPDY 的时候就已经意识到了这些问题,于是就另起炉灶搞了一个基于 UDP 协议的“QUIC”协议,让 HTTP 跑在 QUIC 上而不是 TCP 上。 而这个“HTTP over QUIC”就是 HTTP 协议的下一个大版本,HTTP/3。
UDP 是不可靠传输,数据包在接收端没有处理顺序,即使中间丢失一个包,也不会阻塞整条连接,其他的资源会被正常处理,而 QUIC 在 UDP 上实现了 HTTP 流的可靠传输。
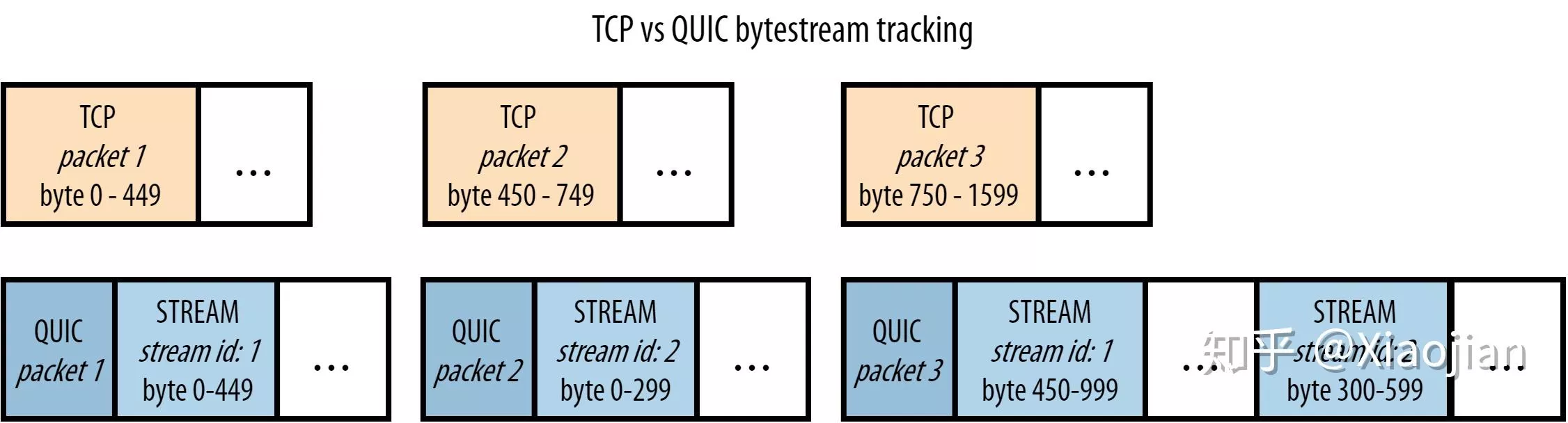
连接上不存在阻塞:QUIC 知道自己传输的是 HTTP 流,如上图,当 packet2 丢失,且后续的 packet 已经到达,QUIC 会查看 packet3 的流ID,发现与 packet1 是同一个流(stream1),且字节范围是连续的,因此可以直接将 packet3 交付给浏览器进行处理,而不用等待 packet2 重传。
单个流上的阻塞:对于 packet4,它属于 stream2,但其字节范围前缺失了 0-299,因此,QUIC 会缓存 packet4,等待 0-299 的 packet,也就是 packet2 到达后再交付给浏览器。
这意味着,想要发挥出 HTTP/3 的优势,需要在单个TCP连接上经常有多个并发流,这就需要浏览器有一个良好的分配策略。
存在的问题:
QUIC(UDP) 并不保证请求和响应的顺序一致,就像上面的例子,stream2 可能比 stream1 先交付给浏览器进行处理。对于一些重要的资源 121212 的传输顺序可能并不比 111222 好,这是显而易见的。
1 | 使用多路复用(较慢): |
数据包的丢失通常是连续的一小段,QUIC的多路复用后,帧的交错传输可能导致两个流恰好都有帧丢失而阻塞。
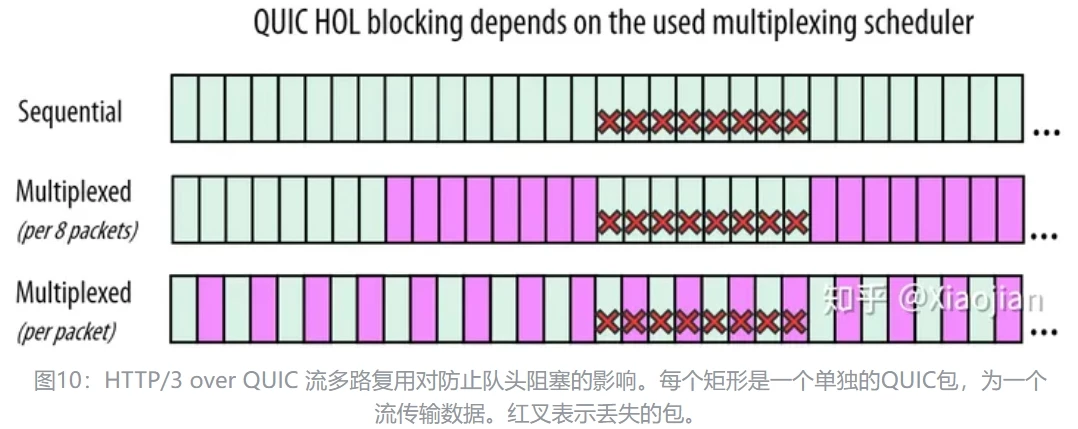
大多数 QUIC 实现很少同时在单个TCP连接上传输多个流。因为如果其中一个数据包丢失,则会立即导致其所含帧所属的流被阻塞。一个QUIC数据包可能携带了多个来自不同流的帧,一旦该包丢失,后果是灾难性的。
多路复用是否重要:
虽然仍然存在一些问题,但多路复用绝对是一个有用的特性
- 对于渐进式图像渲染、文件上传下载、视频等增量处理场景,多路复用可以显著提高性能,基于流与帧的概念,无需等待整个资源加载完毕。
- 网页零碎的小文件请求,即使数据包发生丢失,也不会对其他文件造成太多的延迟。
- QUIC的多路复用允许改变响应的顺序,并为高优先级的响应中断低优先级的响应。
- 配合CDN分发,缓存在CDN上的资源可以更快响应,而未缓存的资源将从服务器获取,但不会阻塞其它流的传输。
连接建立
QUIC 首次连接只需要1-RTT,基于 UDP 不需要 TCP 的三次握手,且内部包含了 TLS,它在自己的数据包中携带 TLS 加密等必要参数,加之 QUIC 使用的是 TLS 1.3,因此仅需 1-RTT 就可以同时完成建立连接与密钥协商。
在第二次连接的时候,应用数据包可以和 QUIC 握手信息(连接信息 + TLS 信息)一起发送,达到 0-RTT 的效果。
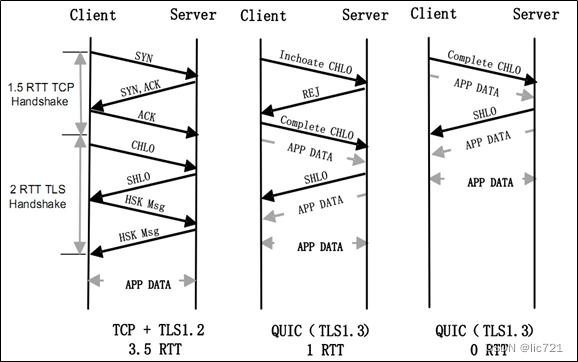
QUIC 数据包中包含连接 ID(Connection ID),这是连接迁移的基础。
连接迁移
基于 TCP 传输协议的 HTTP 协议,由于是通过四元组(源 IP、源端口、目的 IP、目的端口)确定一条 TCP 连接。
切换网络时至少会有一个因素发生变化,导致连接发生变化。当连接发生变化时,如果还使用原来的 TCP 连接,则会导致连接失败,就得等原来的连接超时后重新建立连接,所以我们有时候发现切换到一个新网络时,即使新网络状况良好,但内容还是需要加载很久。如果实现得好,当检测到网络变化时立刻建立新的 TCP 连接,即使这样,建立新的连接还是需要几百毫秒的时间。
QUIC 连接不以四元组作为标识,而是使用一个 64 位的随机数,这个随机数被称为 Connection ID,即使 IP 或者端口发生变化,只要 Connection ID 没有变化,那么连接依然可以维持。
其它
QUIC 重新实现了 TCP 协议的 Cubic 算法进行拥塞控制,也就是慢启动、拥塞避免、快速重传和快速恢复。并在此基础上进行了改进。
- 热插拔 TCP 中如果要修改拥塞控制策略,需要在系统层面进行操作。QUIC 修改拥塞控制策略只需要在应用层操作,并且 QUIC 会根据不同的网络环境、用户来动态选择拥塞控制算法。
- 前向纠错 FEC QUIC 使用前向纠错(FEC,Forward Error Correction)技术增加协议的容错性。一段数据被切分为 10 个包后,依次对每个包进行异或运算,运算结果会作为 FEC 包与数据包一起被传输,如果不幸在传输过程中有一个数据包丢失,那么就可以根据剩余 9 个包以及 FEC 包推算出丢失的那个包的数据,这样就大大增加了协议的容错性。空间换时间。
- 单调递增的 Packet Number TCP 为了保证可靠性,使用 Sequence Number 和 ACK 来确认消息是否有序到达。发生超时重传时请求的 Seq 不变,响应的 Ack 也不变,无法区分是原始请求的 Ack 还是重传请求的 Ack。QUIC 使用 Packet Number 来区分,每个 Packet Number 都是单调递增的,发生重传时,响应的 Ack 也是唯一的。
- 更多的 ACK 块 接收方收到发送方的消息后都应该发送一个 ACK 回复,表示收到了数据。但每收到一个数据就返回一个 ACK 回复太麻烦,所以一般不会立即回复,而是接收到多个数据后再回复,TCP SACK 最多提供 3 个 ACK block。但有些场景下,比如下载,只需要服务器返回数据就好,但按照 TCP 的设计,每收到 3 个数据包就要“礼貌性”地返回一个 ACK。而 QUIC 最多可以捎带 256 个 ACK block。在丢包率比较严重的网络下,更多的 ACK block 可以减少重传量,提升网络效率。
QUIC 也实现了流量控制,两个级别:连接级别(Connection Level)和 Stream 级别(Stream Level)。
HTTPS
超文本传输安全协议(Hyper Text Transfer Protocol over Secure Socket Layer,HTTPS),是一种通过计算机网络进行安全通信的传输协议。HTTPS 经由 HTTP 进行通信,但利用 SSL / TLS 来加密数据包。
目的:提供对网站服务器的身份认证,保护交换数据的隐私与完整性。
HTTP 是明文传输的,数据在传输过程中可能被窃听、篡改,而 HTTPS 则通过 SSL/TLS 协议对数据进行加密,保证数据的机密性和完整性。
安全传输层协议(Transport Layer Security,SSL/TLS),是介于 TCP 和 HTTP 之间的一层安全协议,不影响原有的 TCP 协议和 HTTP 协议。SSL 是 TLS 的前身。
SSL 1.0 – 由于安全问题从未公开发布。
SSL 2.0 – 1995年发布。2011年弃用。存在已知的安全问题。
SSL 3.0 – 1996年发布。2015年弃用。存在已知的安全问题。
TLS 1.0 – 1999年作为SSL 3.0的升级发布。计划在2020年弃用。
TLS 1.1 – 2006年发布。计划在2020年弃用。
TLS 1.2 – 2008年发布。
TLS 1.3 – 2018年发布。
参考:
TLS 详解握手流程
图解 HTTPS:RSA 握手过程
HTTPS ECDHE 握手解析
JavaScript Guidebook-HTTPS
TLS握手
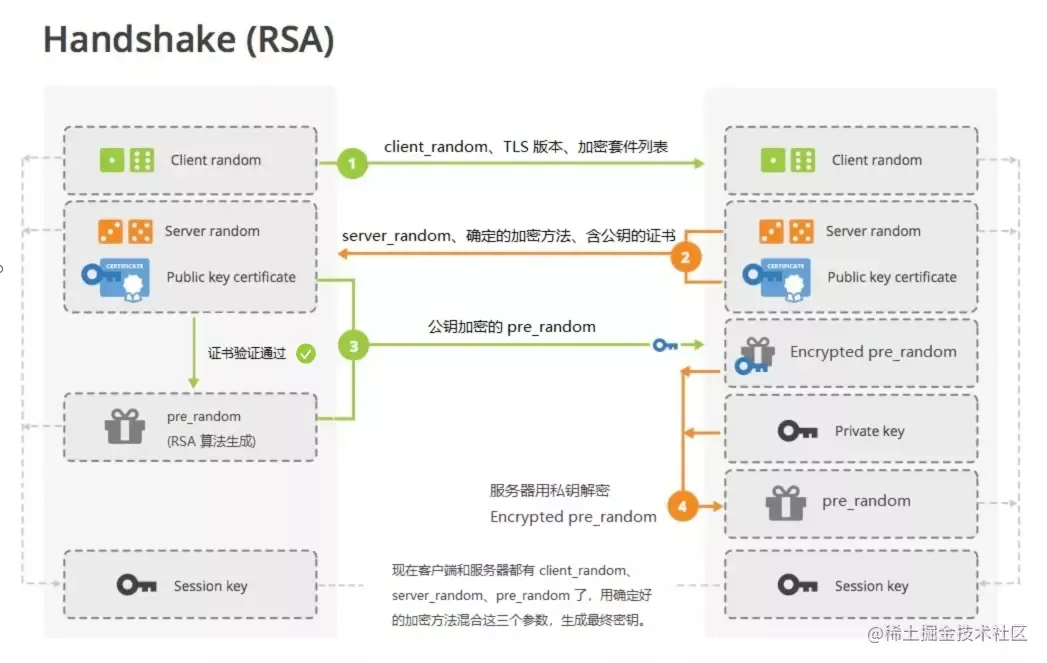
传统TLS使用RSA握手:
- 客户端发送 Client Hello 消息,包含支持的TLS版本、加密套件、客户端随机数client_random。
- 服务端返回 Server Hello 消息,包含确定的TLS版本、选择的加密套件、服务端随机数server_random。
- 服务端继续发送 Certificate 数字证书 (证书中附带公钥)。
- Client Finish 客户端验证证书和签名,若通过则生成一个随机数pre_random作为预主密钥,并用RSA公钥加密后发送给服务端。
- Server Finish 服务端通过RSA私钥解密获得pre_random。此 pre_random 只有服务端和客户端知道,除非私钥泄露。
- 最后双方根据 client_random、server_random、pre_random 生成主密钥,用于后续的通信加密。
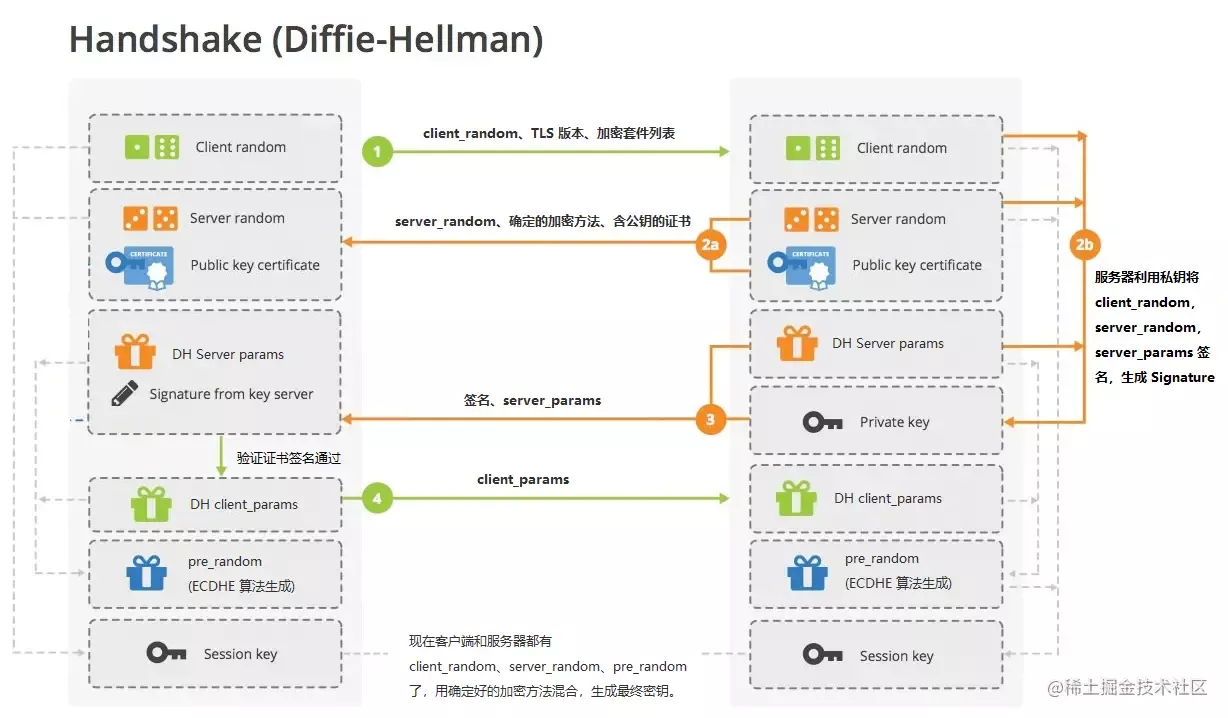
TLS1.2使用DH握手:
与RSA区别主要在于pre_random的生成方式,RSA在客户端生成后使用公钥加密发送给服务端,DH使用ECDHE密钥交换算法生成。
1 | 1.浏览器向服务器发送随机数 client_random,TLS 版本和供筛选的加密套件列表。 |
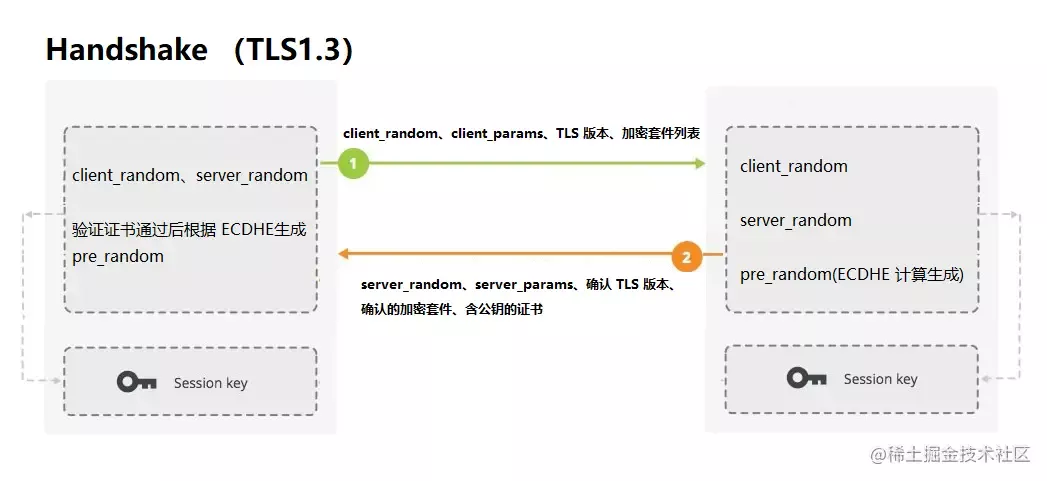
TLS1.3握手:
TLS1.3将握手过程简化,只需要1-RTT,并废除了 RSA 等不安全算法。
RSA 算法的废除不仅因为已经能够被破解,同时还缺少前向安全性。
前向安全:能够保护过去进行的通讯不受密码或密钥在未来暴露的威胁。
1 | // 原 DH 握手 |