前言
浏览器数据存储可以分为HTTP缓存和离线存储,也可以合称为缓存。
离线存储有 Cookie、WebStorage、IndexedDB 等,本文主要讨论HTTP缓存,即由 Cache-Control 等响应头控制的,一种保存资源副本并在下次请求时复用该副本的技术。
缓存作用:减轻服务器压力,提高网页性能,减少资源加载时间。
存储位置
按缓存位置可分为:
- Service Worker 一个服务器与浏览器之间的中间人角色(独立线程),可以拦截当前网站所有的请求,具有离线缓存的能力。
- Memory Cache 内存缓存
- Disk Cache 磁盘缓存
- Push Cache
优先级:Service Worker > Memory Cache > Disk Cache > Push Cache
Service Worker
Service Worker 是运行在浏览器背后的独立线程,一般用于实现离线缓存、消息推送等功能。充当服务器与浏览器之间的中间人角色,可以拦截当前网站所有的请求。
Service Worker 的缓存与浏览器其他内建的缓存机制不同,它可以让我们自由控制缓存哪些文件、如何匹配缓存、如何读取缓存,并且缓存是持续性的。
需要按规则写一个 sw.js 注册激活 Service Worker,如下:
1 | /* 判断当前浏览器是否支持serviceWorker */ |
sw.js 中监听 install 事件,开启缓存,监听 fetch 事件,拦截全站请求,如下:
1 | /* 监听安装事件,install 事件一般是被用来设置你的浏览器的离线缓存逻辑 */ |
注意:
- 使用 SW 后,传输协议必须为 HTTPS。因为涉及到请求拦截,所以必须使用 HTTPS 协议来保障安全。
- 当 SW 没有命中缓存的时候,需要手动调用 fetch 函数获取数据,这意味着还会受其它 HTTP 缓存机制影响。
- 无论从 Memory Cache 中还是从网络请求中获取的数据,浏览器都会显示我们是从 SW 中获取的内容。
- 注册 SW 后,需要等待下一次刷新页面才能生效。
- SW 运行在 Worker 线程中,无法操作 DOM,也无法操作 Cookie。
- SW 设计为完全异步,同步API(如XHR和localStorage)不能在 SW 中使用。
SW 这个技术内容还是很多的,现在只是简单介绍了一下,本站也开启了 SW,后续有时间再深入学习。
参考:
一文搞懂前端service-worker 技术
网易云课堂 Service Worker 运用与实践
Memory Cache
Memory Cache 是内存缓存。存储短时间内频繁访问的资源,读取速度快,但是容量小。会随着进程的关闭而释放。
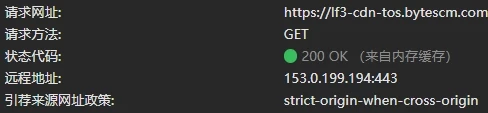
Memory Cache 在缓存资源时不受开发者控制,也不受 HTTP 协议头的约束,同时资源的匹配也并非仅仅是对 URL 做匹配,还可能会对 Content-Type,CORS 等其他特征做校验。是否缓存资源,以及缓存多久,都是由浏览器策略决定的。
Disk Cache
Disk Cache 是磁盘缓存。读取速度慢于内存,但容量大,持久性强。不会随着进程的关闭而释放。
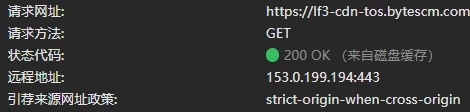
Disk Cache 会根据 HTTP 头中的某些字段判断哪些资源需要缓存。
一些关键的、较小的、访问频繁的 Disk Cache 资源可能会被加载到 Memory Cache 中,这样可以提高访问速度。
即使在跨站点的情况下,相同地址的资源一旦被硬盘缓存下来,且命中缓存,就不会重新请求。
Push Cache
Push Cache 是推送缓存。HTTP/2 中的概念,当服务器使用 Server Push 功能主动推送资源时,这些资源会被缓存到 Push Cache 中,以备将来使用。
当以上三种缓存都没有命中时,它才会被使用。且只在会话(Session)中存在,一旦会话结束就被释放,并且缓存时间也很短暂,在 Chrome 浏览器中只有 5 分钟左右,同时它也并非严格执行 HTTP/2 头中的缓存指令。
HTTP/2 push is tougher than I thought 提到的特性:
- 所有的资源都能被推送,并且能够被缓存,但是不同浏览器支持的程度不同。
- 可以推送 no-cache 和 no-store 的资源
- 一旦连接被关闭,Push Cache 就被释放
- 多个页面可以使用同一个 HTTP/2 的连接,也就可以使用同一个 Push Cache。这主要还是依赖浏览器的实现而定,出于对性能的考虑,有的浏览器会对相同域名但不同的 tab 标签使用同一个 HTTP 连接。
- Push Cache 中的缓存只能被使用一次
- 浏览器可以拒绝接受已经存在的资源推送
- 可以给其他域名推送资源
总之,战未来的东西,不必纠结,了解即可。
缓存类型
按缓存类型可分为:
- 强制缓存 通过
Expires/Cache-Control控制,命中强缓存时不会发起网络请求,资源直接从本地获取,浏览器显示状态码200 from cache - 协商缓存 通过
Last-Modified/If-Modified-Since和Etag/If-None-Match控制,开启协商缓存时向服务器发送的请求会带上缓存标识,若命中协商缓存服务器返回304 Not Modified表示资源未修改,浏览器可以使用本地缓存,否则返回200 OK正常返回数据。
强缓存和协商缓存,都属于 Disk Cache,也就是狭义上的 HTTP 缓存。
强制缓存
当客户端请求后,会先检查是否命中缓存(缓存存在且未过期)。如果命中则直接返回,未命中才会发送实际 HTTP 请求,响应后再写入 Disk Cache。
受两个 HTTP 字段的控制:
- Expires 是 HTTP1.0 的字段,在响应时告诉浏览器在过期时间前可以直接使用缓存。
- Cache-Control 是 HTTP1.1 增加的字段,优先级高于 Expires,可以控制缓存的存储策略。
Expires
Expires 设置缓存过期时间,是一个绝对时间
1 | Expires: Wed, 21 Oct 2024 07:28:00 GMT |
存在问题:
- 服务器和客户端时间可能不一致,导致缓存混乱。
- 用户可以手动修改客户端时间,导致缓存失效。
- GMT格林尼治标准时间写法复杂。
Cache-Control
HTTP1.1 引入了 Cache-Control 字段,优先级高于 Expires,可以控制缓存的存储策略。
常用的值:
max-age=xxx指定缓存的最大有效时间,单位为秒。no-cache不使用强缓存,需要使用协商缓存。no-store绝对不缓存。public可以被所有用户缓存,包括终端用户和 CDN 等中间代理服务器。private只能被终端用户缓存,中间代理服务器不能缓存。must-revalidate如果超过了max-age的时间,浏览器必须向服务器发送请求,验证资源是否还有效。
设置 max-age=3600 表示资源在 1h 内有效,超过才会向服务器发起请求。
这些值可以混用,以逗号分隔,如 Cache-Control: max-age=3600, public。
冲突时考虑优先级,no-store > no-cache > max-age。
max-age=0 和 no-cache:
- 从规范定义来说,两者不同,
max-age到期是应该(SHOULD)重新验证,而no-cache是必须( MUST )重新验证。 - 但实际情况以浏览器实现为准,大部分情况两者行为是一致的。
- 如果是
max-age=0, must-revalidate就和no-cache等价。
在 HTTP/1.1 之前,如果想使用 no-cache,通常是使用 Pragma 字段,如 Pragma: no-cache(这也是 Pragma 字段唯一的取值)。但该字段并不是标准字段,没有确切的规范,缺乏可靠性,自从 HTTP/1.1 开始,Expires 逐渐被 Cache-control 取代。
为了兼容 HTTP/1.0 和 HTTP/1.1,实际项目中两个字段都会设置。
协商缓存
当强制缓存失效时,就会进入协商缓存阶段。
协商缓存会向服务器发送请求,并带上资源状态标识,根据服务器返回的响应决定是否使用缓存。
协商缓存的请求与正常请求是一样的,都会实际到达服务器。
协商的两种情况:
- 返回 304 Not Modified,表示资源未修改,可以继续使用缓存。返回 304 时仅返回头部信息,不返回资源内容。
- 返回 200 OK,表示资源已更新,获取最新资源并更新缓存。
协商缓存可以和强制缓存一起使用,作为在强制缓存失效后的一种后备方案。
由两组字段控制:
Last-Modified/If-Modified-Since是基于时间的协商缓存,资源在服务器上最后修改时间。Etag/If-None-Match是基于内容的协商缓存,资源内容的唯一标识。
实际开发中,两者都会设置,但校验时应优先考虑 Etag / If-None-Match。
Last-Modified / If-Modified-Since
Last-Modified 由响应头携带,表示资源最后修改时间。在缓存资源时,浏览器会记录这个时间,并在下次请求时会带上 If-Modified-Since 字段,服务器根据这个时间判断资源是否更新。
若 If-Modified-Since 与此时的 Last-Modified 相同,服务器返回 304,表示资源未修改,可以继续使用缓存。
存在问题:
- 如果资源更新的速度是秒以下单位,那么该缓存是不能被使用的,因为它的时间单位最低是秒。
- 如果文件是通过服务器动态生成的,那么该方法的更新时间永远是生成的时间,起不到缓存的作用,尽管文件可能没有变化。
- 若文件存在重复上传,或打开文档然后又保存,都可能会造成时间的修改,但内容实际上并没有变化。
为了解决这两个问题,HTTP/1.1 增加了 ETag 和 If-None-Match。
Etag / If-None-Match
Etag 由响应头携带,是资源的唯一标识,如文件hash值。在缓存资源时,浏览器会记录这个标识,并在下次请求时会带上 If-None-Match 字段,服务器根据这个标识判断资源是否更新。
若 If-None-Match 与此时的 Etag 相同,服务器返回 304,表示资源未修改,可以继续使用缓存。
ETag 在标识前面加 W/ 前缀表示用弱比较算法(If-None-Match 本身就只用弱比较算法)。ETag 还可以配合 If-Match 检测当前请求是否为最新版本,若资源不匹配返回状态码 412 错误(If-Match 不加 W/ 时使用强比较算法)。
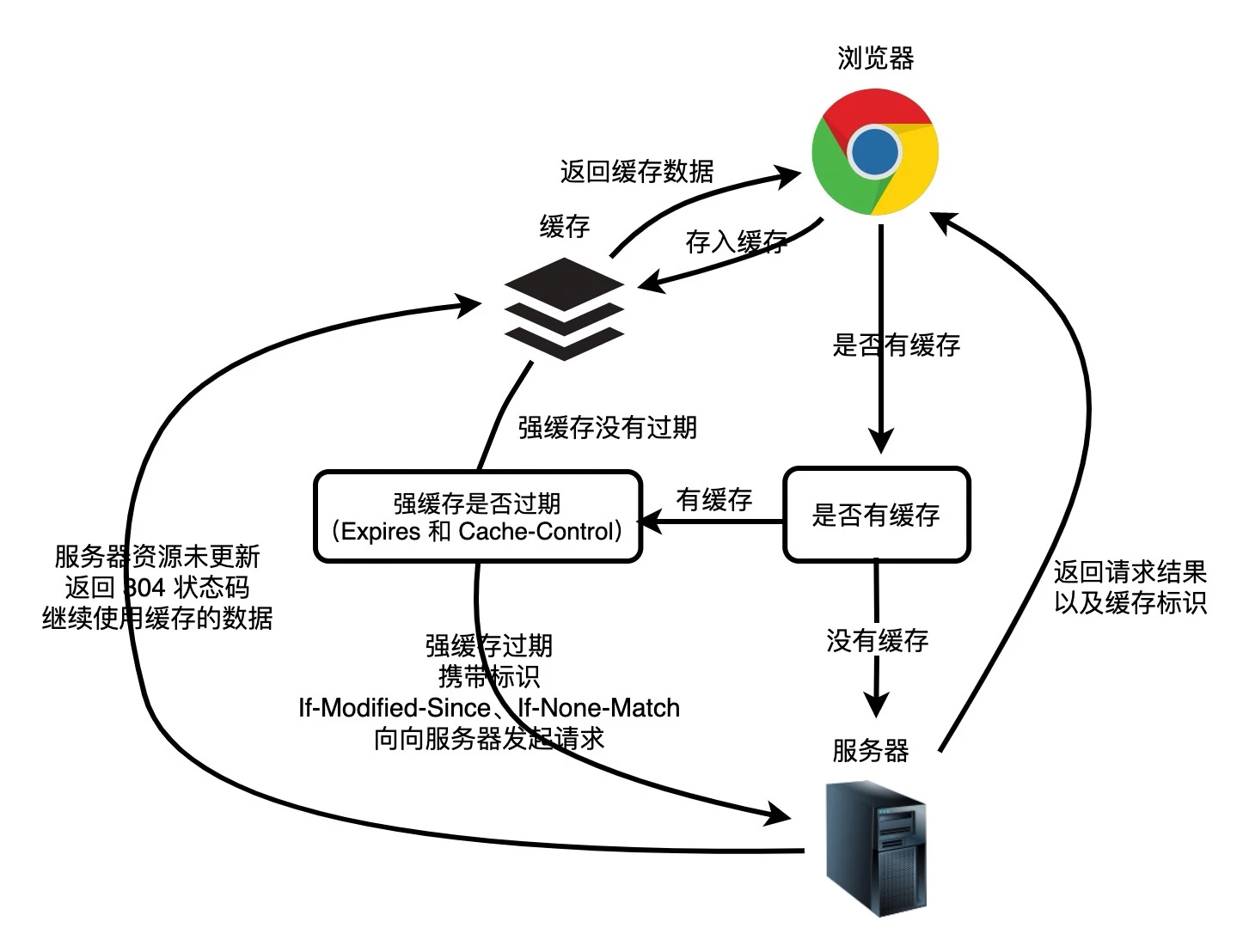
缓存读取规则
缓存读取规则(优先级):
- 从 Service Worker 中获取内容
- 查看 Memory Cache
- 查看 Disk Cache
- 有缓存且未过期,直接使用,不发送请求
- 有缓存但已过期,发送请求验证,进入协商缓存,返回 304 或 200
- 查看 Push Cache
- 发送请求获取资源
- 将响应写入 Disk Cache
- 将响应写入 Memory Cache(浏览器策略)
- 将响应写入 Service Worker 的 Cache Storage
浏览器行为
用户对浏览器的不同操作,还会触发不同的缓存读取策略。
- 浏览器前进/后退具有特殊缓存,Backward/Forward Cache,即 BF Cache,是指浏览器在前进后退过程中,会应用更强的缓存策略,表现为 DOM、window、甚至 JavaScript 对象被缓存,以及同步 XHR 也被缓存。BF Cache 是一种浏览器优化,HTML 标准并未指定其如何进行缓存,因此缓存行为是与浏览器实现相关的。
- 直接输入地址、刷新、跳转链接,都会触发正常的浏览器缓存读取策略。
- 强制刷新 (Ctrl + F5),浏览器不使用缓存,此时发送的请求头部均带有 Cache-control: no-cache(为了兼容,还带了 Pragma: no-cache )。服务器直接返回 200 和最新内容。
最佳实践
对于经常变动的资源,使用 Cache-Control: no-cache
对于不常变动的资源,使用 Cache-Control: max-age=31536000,即 1 年过期,但文件名需要带上 hash 值或版本号,在文件变化后让url也改变,不再命中之前的缓存。
实操案例
1 |